Llevo siguiendo a Magenta, el grupo de investigación musical de Google, desde que en 2017 sacaron NSynth, un sintetizador neuronal que llegó a tener hasta su versión física (de la cual conseguí una copia). Su apuesta no ha cambiado en una década: la IA como instrumento para músicos, no como su sustituto.
Su último modelo, Magenta RealTime 2 (MRT2), da por fin un salto muy interesante: corre abierto y en local, en un portátil, sin pasar por la nube. El modelo deja de ser un servicio remoto y se convierte en una herramienta independiente (generas y tocas música en tiempo real, respondiendo al instante a texto, MIDI o audio). Para mí eso lo cambia todo: ya no dependes de un modelo alojado en la nube, como Lyria RealTime. El modelo baja de la nube y se queda en tu mesa.
Magenta no solo abre el modelo: publica además una colección de instrumentos y experiencias de ejemplo hechos con él, pensados para que músicos y desarrolladores lo integren en su propio software. Sirven para verlo en acción y dejan clara la intención original: clonar un sonido y tocarlo, mezclar estilos sobre la marcha, montar acompañamientos en vivo con muy baja latencia. Esa es la propuesta oficial, convertir el modelo en instrumentos. Nosotros, a partir de aquí, tiramos por otro lado.
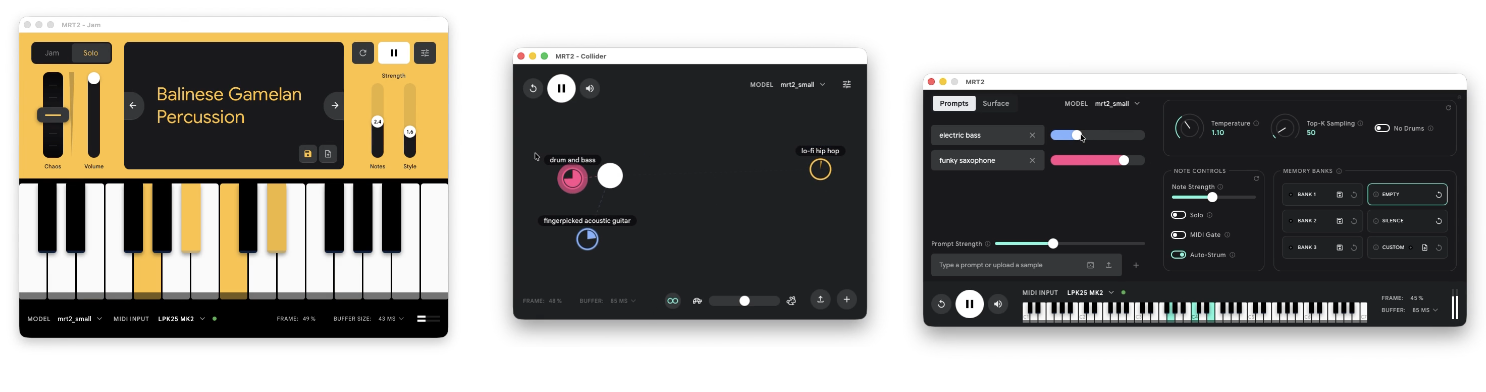
Esta guía no va de usar MRT2 como instrumento (que también). Va de darle la vuelta. Hice una implementación propia con dos intenciones: usarlo y, sobre todo, entenderlo por dentro. Y al abrirlo apareció algo curioso: en lugar de tocar el instrumento, podía recorrer el mapa de sonidos que el modelo ya distingue de forma nativa. Usar las palabras no como prompt, sino como una manera de cartografiar ese espacio latente y volverlo un sistema musical finito: nuestro propio mapa.
Porque por dentro MRT2 es un sistema discreto. De lo que le mandes, sea audio o texto, va a generar una señal sonora continua, y para eso hace tres cosas encadenadas: convierte lo que le pides (una palabra, un audio) en un vector de 768 números; comprime ese vector a 12 símbolos (los tokens) de un vocabulario cerrado; y, a partir de esos símbolos, va generando el audio a trozos (por muestreo), como fotogramas, unas 25 veces por segundo. No entrega una pista cerrada: entrega un flujo que puedes empujar mientras suena. Esta guía abre esa cadena, paso a paso, y enseña dónde metimos mano.
Aquí irá un vídeo de la interfaz que construimos y de cómo suena. Ayuda a ver de un vistazo el objetivo: usar el proyecto de Google para explorar cómo funciona el modelo y, a la vez, construir con él nuestra propia interfaz musical.
Cada figura introduce un solo concepto, de lo general a lo concreto: prosa breve → diagrama → pie. Los dibujos son SVG (nítidos a cualquier escala). Es la versión divulgativa de un experimento que también existe como instrumento jugable: el tapiz que suena.
1 · El panorama
de una palabra a un río de audio
El recorrido completo de un vistazo. A la izquierda entra tu indicación (texto o audio); a la derecha sale música, no como pista cerrada sino como ese flujo. Entre medias, los dos cuellos de botella que vertebran toda la guía: la compresión a un vector de 768 números (el embedding, que vemos enseguida) y, sobre él, la compresión a 12 símbolos (la cuantización, justo después). Cada flecha es uno de esos pasos, abierto en canal.
El recorrido completo. Dos cuellos de botella deliberados (768 números y 12 símbolos) y una salida que es un flujo, no una pista. La flecha ámbar es lo que añadimos nosotros: tratar el cuantizador como un atlas.
2 · Una palabra es un punto en 768 dimensiones
el embedding (incrustación)
Cuando el modelo recibe «ocean» no piensa en olas ni en su significado: la convierte en un punto dentro de un espacio de 768 dimensiones. Es decir, 768 números, cada uno una coordenada (imposible de dibujar, pero la intuición es la de cualquier mapa). Y lo que importa no es el punto en sí, sino las distancias entre puntos: esa distancia es musical. «ocean» y «underwater» caen casi en el mismo sitio, y suenan a cosas parecidas; «thrash metal» se va a la otra punta del espacio, y suena a otro mundo. La regla es justo esa: cerca quiere decir que suena parecido.
Esa cercanía se mide con el coseno: el ángulo entre dos puntos vistos desde el centro. Dos términos casi en la misma dirección dan coseno próximo a 1 (muy cerca); en direcciones opuestas, próximo a 0 o negativo. Nos acompañará el resto de la guía: es la regla con la que medimos todo el mapa.
El embedding. Una palabra (o un audio) se vuelve un punto en 768 dimensiones, casi unitario. La distancia entre puntos es musical: vecinos suenan parecido. Todo lo demás se construye sobre esta idea.
Dos etapas, y por qué esto vale más allá de MRT2
Conviene separar dos cosas que solemos confundir. Que «ocean» acabe en ese punto de 768 lo decide una red neuronal: es una función aprendida, sin fórmula que puedas seguir a mano. Lo que viene después, convertir ese punto en símbolos y volver a montarlo, es matemática sencilla, tablas y sumas (como verás enseguida). Y casi cualquier modelo actual arranca igual, texto a embedding; la diferencia está en qué hace luego con esos vectores.
Dos etapas. Primero una red convierte el texto en un punto de 768 números (eso es lo aprendido). Después, la cuantización lo empaqueta en símbolos con tablas y sumas. Lo primero es propio de cada modelo; lo segundo es el mecanismo que vamos a abrir.
3 · Cuantizar: del valor continuo al símbolo
la carta de colores y el codebook
La cuantización es una idea vieja y muy usada en señales y compresión: representar algo continuo con un conjunto finito de valores de referencia, igual que una imagen reduce millones de colores a una paleta. Aquí hacemos lo mismo, pero con vectores.
Y es que un punto de 768 decimales es demasiado para un transformer: estos modelos no manejan valores continuos, sino símbolos de un vocabulario finito, como un idioma maneja un número limitado de letras. Cuantizar es sustituir cada valor continuo por el más parecido dentro de un conjunto cerrado de valores de referencia. Ese conjunto es el codebook (un diccionario fijo de puntos-tipo), y a cada una de sus entradas la llamamos centroide, porque representa el centro de una región del espacio.
Verlos como una paleta de colores igual lo hace más claro: tienes un tono exacto (tu vector) y una paleta cerrada de 1024 tonos de referencia (el codebook). Eliges el más cercano y te quedas con su número, no con el color original. Pierdes matiz; ganas un símbolo manejable. Eso es cuantizar.
La carta de colores. El codebook es la paleta; cada celda, un centroide (un punto de referencia en 768 dimensiones). Cuantizar = sustituir tu punto por el centroide más próximo y quedarte con su índice. (En el siguiente paso: por qué no basta una paleta, sino doce.)
El codebook por dentro: abrir un token y reconstruir
Vale la pena ver el mecanismo. Un centroide es otro vector de 768, un punto fijo de referencia. El codebook es una tabla con 1024 de esos puntos. Y abrir un token es leer una fila: el token es un número, vas a la tabla y lees esa fila. Lo que hay ahí es el centroide.
Abrir un token es leer una fila. El codebook es una tabla de 1024 centroides (cada uno, un vector de 768). El token es el número de fila: no se calcula nada, se consulta.
¿Y reconstruir? Igual de directo: lees las filas de los tokens (12 en MRT2) y las sumas. Esa suma recupera, casi clavado, el vector original. Por eso un estilo entero cabe en 12 símbolos.
Reconstruir es sumar. Lees los centroides de los 12 tokens y los sumas: recuperas el vector original con un coseno de ~0,96. Esa es la razón de que 12 símbolos basten.
4 · RVQ: doce capas que afinan el tono
cuantización residual
Una sola paleta de 1024 tonos es muy basta: el tono elegido se queda lejos del original. De ahí la R de RVQ (Residual Vector Quantization, cuantización vectorial residual). La idea: tras elegir el primer tono, miras lo que aún falta (el residuo) y eliges otro tono que lo corrija; y así doce veces, cada nivel con su propia paleta. El estilo no es un símbolo: son doce. Y la reconstrucción mejora rápido: con 1 token rondas un coseno de 0,5; con los 12, ≈0,96.
Coarse-to-fine. El primer nivel da el trazo grueso; los siguientes, el detalle. La curva sube deprisa y se aplana: los últimos niveles solo pulen. El nivel 1 (el más grueso) será nuestro mapa.
5 · Los índices no son coordenadas
una trampa sutil
Dos estilos que suenan parecido (funk y disco, con un coseno alto de 0,77, o sea muy cerca) tienen tokens de aspecto dispar: funk da 412, 88, 5, 901… y disco 39, 991, 220, 7…, sin apenas prefijo común. Tentador concluir que están lejos, y sería falso. Los 1024 centroides están numerados de forma arbitraria: el número es una etiqueta de posición, no una medida. La cercanía solo reaparece cuando abres los tokens y sumas los centroides a los que apuntan; ahí, sobre el vector reconstruido, funk y disco vuelven a quedar juntos.
Ruta, no coordenada. Los índices RVQ son punteros a centroides; su orden no significa cercanía. Pero sumar esos centroides recupera un vector que sí respeta las distancias musicales. Esto es lo que legitima usar el codebook como mapa.
6 · Un sistema discreto que se toca en tiempo real
qué es del modelo y qué es nuestro
Conviene separar dos cosas que se mezclan con facilidad. Una es del modelo: MRT2 es, de fábrica, un generador de música en tiempo real; responde al instante y nunca se detiene (ese río de fotogramas del principio). La otra es nuestra: la interfaz que construimos para gobernarlo, cómo le vamos diciendo por dónde ir mientras suena.
Lo que montamos es sencillo de contar. En lugar de reescribir un prompt cada vez, mandamos al motor, en caliente, el vector de estilo ya cuantizado, y dejamos que interpole suavemente de uno a otro sin cortar el sonido. Mover el estilo deja de ser escribir: es empujar un punto por el mapa y oír cómo el río cambia de color.
Nuestra capa de control. El estilo viaja como vector, no como texto; el motor interpola entre puntos y nunca corta el río de audio. Este es el mismo camino por el que el tapiz hará sonar una provincia.
7 · De constelaciones a territorio
nuestra pregunta, y dos formas de responderla
Aquí aparece lo que de verdad buscábamos. Si cada palabra es un punto y la cercanía es musical, ¿qué ocurre si en vez de pedir música soltamos términos (estilos, nombres, verbos, colores) y miramos dónde caen y cómo suenan? ¿Se puede ver el mapa entero, no solo los lugares que sabemos nombrar?
Hay dos formas de intentarlo. La de constelaciones: eliges unos puntos con nombre (por ejemplo 24 géneros) y los proyectas; el mapa toma la forma de lo que elegiste y solo navegas por ahí. La otra, la de territorio: en vez de nombrar, muestreas la rejilla nativa del propio modelo y alcanzas también las zonas anónimas. Nosotros nos pasamos a la segunda.
Cambio de paradigma. Las constelaciones quedan limitadas por lo que sabes nombrar. El territorio recorre la partición que el modelo trae de fábrica, y ahí aparecen los vecindarios sin nombre.
8 · El codebook grueso = 1024 provincias = 32²
la partición nativa
Volvamos al codebook, pero a su primer nivel (el más grueso, el del primer paso de la cuantización residual). Tiene 1024 centros, y cada uno es una provincia: una región que el modelo distingue de serie. Como 1024 = 32², se dibuja limpiamente como un tapiz de 32×32. Esos centros son reales y legibles del fichero del cuantizador (vienen negados: el centro de la provincia i es −codebook[0][i]).
Lo real y lo elegido. Que haya 1024 centros, y que el modelo los distinga de serie, es real y nativo. Dibujarlos como un tapiz de 32×32 ya es decisión nuestra, una elección estética (1024 = 32² lo pone fácil). Pero cada casilla es un punto de verdad, que podemos decodificar y hacer sonar.
9 · Manera B: rotular cada provincia por su centro
poner nombres a lo anónimo
El espacio no trae nombres propios. Para etiquetar una provincia hay dos caminos. Manera A: ver qué palabras caen dentro de la celda (su token 0). Manera B: ir al centro de la celda y preguntar qué palabra del vocabulario tiene más cerca (un retrieval). Elegimos la B: caracteriza también las celdas vacías y no depende de que algo «caiga» justo ahí.
Recuperación, no clasificación. Para cada uno de los 1024 centros buscamos la palabra más próxima del vocabulario. El rótulo es un préstamo del lenguaje sobre un punto que existía sin él.
10 · El vocabulario: tres capas con procedencia
la vara de medir
La manera B necesita un buen vocabulario, porque es la vara de medir con la que nombramos. Lo construimos en tres capas con procedencia: la folksonomía musical (lo que la gente usa para etiquetar música, alto en señal), un registro evocador cotidiano y una cosecha del libro Retromania. En total ~5.500 palabras. Importante: solo nombran; el territorio sigue siendo del modelo.
Procedencia como dato. Cada palabra sabe de dónde viene. Eso permite, después, colorear el tapiz por capa (o por familia musical) y razonar sobre qué tipo de lenguaje cubre cada zona.
11 · t-SNE: el cono y por qué «respira»
aplanar 768 dimensiones a un plano
Para poder dibujar algo de 768 dimensiones hay que bajarlo a 2, y a eso se le llama reducción de dimensionalidad: buscar un plano que conserve lo esencial de la nube original. Hay dos familias. PCA es lineal, se queda con los ejes donde los datos más varían, como aplastar una sombra contra la pared; rápido, pero si el espacio tiene mañas, deforma. t-SNE es no lineal, le dan igual las distancias globales y solo cuida quién está cerca de quién, colocando cada punto junto a sus vecinos.
Y aquí el espacio tiene una maña importante: es anisótropo, no se reparte por igual en todas las direcciones. Casi todos los vectores apuntan hacia el mismo lado (el llamado efecto cono), así que el coseno crudo sale siempre alto y el PCA lo agolpa todo en una bola. El t-SNE con métrica coseno respira: separa los vecindarios y deja ver el mapa.
Por qué t-SNE. En un espacio cónico, lo lineal aplasta. El t-SNE con coseno despliega los 1024 centros en una nube donde lo cercano sigue cercano, el plano que luego cuadriculamos.
12 · RasterFairy: del t-SNE a la retícula
cuadricular sin romper vecindades
El t-SNE da una nube orgánica; el tapiz necesita una retícula perfecta. El truco (estilo RasterFairy): plantearlo como una asignación óptima 1:1 entre los 1024 puntos y las 1024 casillas de un 32×32, minimizando el desplazamiento total. Cada punto se mueve lo mínimo a su casilla y las vecindades se conservan (desplazamiento medio ≈ 0,10).
Orden sin perder el mapa. No reordenamos al azar: resolvemos el emparejamiento que menos distorsiona. El resultado es un tapiz regular cuyas casillas vecinas siguen sonando parecido.
13 · El tapiz que suena
el instrumento final
Todo confluye aquí. Las 1024 provincias, rotuladas y cuadriculadas, forman un tapiz navegable. Pasas el ratón y lees; haces clic y la provincia suena: mandamos su centro al motor por el mismo camino del panorama. Y como las casillas vecinas se parecen, recorrerlas con criterio casi compone bandas sonoras.
El círculo se cierra. Lo que empezó como 768 números y 12 símbolos termina como un mapa que se toca. No le pedimos música: recorremos su territorio y escuchamos lo que el modelo distingue.
Guía visual creada el 22 de junio de 2026 a partir del experimento td-magenta. Las figuras son SVG autónomos en Procesos/images/ (guia-fig-01…13). Jardín digital: las cosas están vivas y puede haber erratas o piezas fuera de sitio.
Conexiones
- Magenta RealTime 2 - de texto a música (MusicCoCa, RVQ, tokens) — la teoría a fondo detrás de estas figuras: cuantización, codebook, centroides y los cuatro ingredientes de MRT2
- ¿Somos Fitzcarraldo creando máquinas generativas? — la otra cara: el exceso de pedirle a la máquina que reproduzca lo conocido, frente a aquí, donde recorremos lo que ya distingue